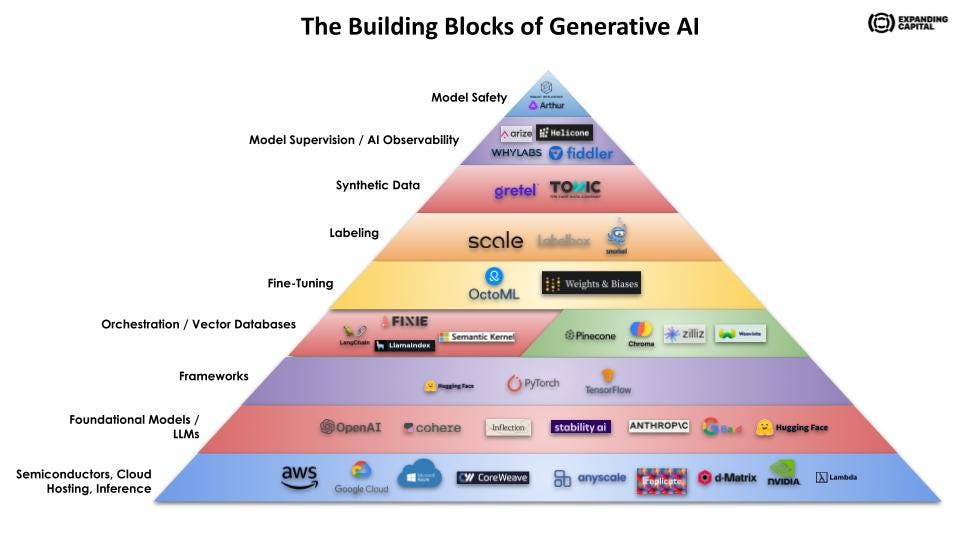
The Building Blocks of Generative AI
A Beginners Guide to The Generative AI Infrastructure Stack

Thank you to Bruno Sanovicz for helping to research this with me.
This article also had input from leading founders and developers in the Generative AI space. Thank you for your time and quotes Will Manidis (CEO, Science.io), Harrison Chase (CEO, LangChain), Alex Ratner & Braden Hancock (CEO, COO, Snorkel.ai), Manu Sharma (LabelBox), Will Jennings, Conor Finan (Comms, CFO, Gretel.ai), Brannin McBee (Founder, CoreWeave), Krishna Gade & Amit Paka (CEO, COO, Fiddler.ai), Sid Sheth & PJ Jamkhandi (CEO, COO, d-Matrix), Pedro Salles Leite (CEO, Innerplay), Faisal Azhar, PhD (AI leader - Program & Product lead LLaMA (by Meta))
If you want to chat more about Gen AI infra shoot me a note here.
For almost a decade, my deep interest in conversational AI has motivated me to explore its potential in boosting productivity and addressing business challenges. I co-founded Humin, a conversational AI CRM, which was later acquired by Tinder. Additionally, I led technology partnerships at Snaps, a customer service conversational AI platform that got acquired by Quiq.
I've been an advocate for conversational AI interfaces and I’ve written about chatbots, conversational commerce, and the future of conversational search. What excites me now is the remarkable progress of Generative AI. It’s already transformed writing, coding, content creation, and holds great promise in fields like healthcare, science, and law.
But it's the foundational components, the essential building blocks of generative solutions, the “picks and shovels”, that have rapidly evolved in terms of technology and venture investment. Keeping up with these advancements has been a (fun) challenge in itself.
The recent acquisitions in this space have also caught my attention. Just two weeks ago, Databricks acquired MosaicML, an infrastructure platform for Generative AI, for an astounding $1.3 billion.
In the past few weeks, I've dedicated time to gaining an understanding of the Generative AI infrastructure landscape. In this post, I aim to provide a clear overview of the key components, emerging trends, and highlight the early industry players driving innovation. I’ll explain foundational models, compute, frameworks, orchestration & vector databases, fine-tuning, labeling, synthetic data, AI observability and model safety.
My goal is to understand and explain these concepts in a simple and straightforward manner. Additionally, I hope to leverage this knowledge potentially to make future growth investments.
By the end of this post, I’ll connect all these concepts by illustrating how two companies utilize the infrastructure stack in a cohesive manner.
Large Language & Foundational Models
Let's start with large language models or LLMs. In the simplest terms, LLMs are computer programs that undergo training using an extensive collection of text and code, including books, articles, websites, and code snippets. The ultimate goal of LLMs is to truly understand the meaning of words and phrases and excel at generating new sentences. It does this in conjunction with something called deep learning.
Foundation models, which are another name for these LLMs, play a vital role as they provide the groundwork for a wide range of applications. In this research, we'll dedicate a significant portion of our focus to this foundational aspect, as the name itself suggests.
These models leverage enormous datasets to learn various tasks. While they may occasionally make errors or exhibit biases, their capacity and efficiency are continually improving.
To bring this concept to life, let's consider a practical example. Imagine you're a writer in search of fresh ideas for a story. By inputting a few words into the model, it can generate a list of potential concepts. I utilized this to receive suggestions for the title of this very article. Similarly, a scientist facing a problem can harness the power of a foundation model by inputting a few words to uncover the required information from a vast amount of data.
Foundation models have sparked a significant transformation in the development of artificial intelligence systems. They power chatbots and other AI interfaces, and their progress owes much to self-supervised and semi-supervised learning. Now, what do these terms mean exactly?
In self-supervised learning, a model learns from unlabeled data by deciphering word meanings based on frequency and context. On the other hand, semi-supervised learning involves training the model using a combination of labeled and unlabeled data. Labeled data refers to instances where specific information is already assigned to the data, such as a dataset with labeled images of bikes and cars. The model can then differentiate between the two using the labeled images and further refine its understanding with the unlabeled ones. I'll dive deeper into the concept of fine-tuning shortly.
Now, when it comes to building applications on top of a foundation model, a crucial consideration arises: should developers opt for an open-source or closed model?
Open-source AI models have their underlying code and architecture publicly accessible and freely available for anyone to use, modify, and distribute. This openness fosters a collaborative environment where developers and researchers can contribute to model improvement, adapt it to new use cases, or integrate it into their own projects.
On the other hand, closed-source AI models keep their code and architecture private, restricting free access to the public. The usage, modification, and distribution of these models are tightly controlled, usually by the company that developed it. This approach aims to safeguard intellectual property, maintain quality control, and ensure responsible usage. Even though external developers and researchers cannot directly contribute to model improvements or adaptations, they can typically interact with the model through predefined interfaces or APIs provided by the entity that owns the model.
Choosing between an open model and a closed model can present its challenges. Opting for an open-source solution means taking on the responsibility of managing infrastructure requirements like processing capabilities, data storage, and network security, which are typically provided by closed model providers.
Throughout the process of writing this, I wanted to understand the models unique benefits and selling points. Most importantly, I sought insights from the builders in the field.
While the viewpoints I encountered may have varied, a few key themes emerged when selecting a base model: the desired precision of the application, the developers team's readiness to handle their own infrastructure, and the inclination to stick with the familiar if sufficient exploration hasn't been conducted.
First and foremost, accuracy is crucial. Depending on the task the model needs to accomplish, the tolerance for errors may differ. For instance, a sales chatbot can handle occasional mistakes, making it suitable to build upon an existing base model. However, consider the case of a self-driving car, where errors could have catastrophic consequences.
Secondly, cloud hosting plays a significant role. For agile startups aiming to maintain lean operations, dealing with computing power, data storage, and technical intricacies can divert their focus from core goals. This is why many startups choose to build on top of a ready-made closed-source platform like Chat-GPT. On the other hand, large corporations equipped with in-house expertise in infrastructure management may lean toward the open-source route to retain control over all aspects and gain a deeper understanding of the system's outcomes.
Finally, business goals exert their influence. Different companies have different agendas, which can sway the decision-making process. Zoom, for example, invested in and utilizes Anthropic, a model tailored to enterprise use cases and security. While Anthropic may not possess a superior system compared to OpenAI, Zoom likely wants to avoid the risk of having its data used by OpenAI/Microsoft, which competes with Teams. These strategic considerations play a significant role in determining the partners companies choose to build their systems with.
The landscape of large language models (LLMs) continues to expand. Here’s a few leading models like OpenAI's GPT4 and DALL-E, Cohere, Anthropic's Claude, LLaMA from Meta AI, StabilityAI, MosaicML and Inflection AI.
OpenAI, a cornerstone in the AI industry, is renowned for its advancements in GPT4 and DALL-E. ChatGPT, a closed-source model with an impressive conversational AI interface, enables bots to hold sophisticated conversations with people, while DALL-E can generate unique images from textual descriptions.
MosaicML, an open-source AI startup, has developed a platform for training large language models and deploying generative AI tools. Recently acquired by Databricks, MosaicML's unique, open-source approach will continue to empower organizations to create their own language models.
Meta AI's contribution to the AI field, LLaMA, is an open-source model. By encouraging other researchers to use LLaMA, Facebook aims to foster the development of new applications and enhance the accuracy of language models.
StabilityAI, renowned for systems like Dance Diffusion and Stable Diffusion, is a leader in open-source music- and image-generating systems. Their goal is to inspire global creativity. The company also boasts MedARC, a foundational model for medical AI contributions.
Anthropic, a closed-source company co-founded by OpenAI veterans, created Claude, a safe and capable language model. Claude stands out as a new model for handling data, setting an early benchmark for responsible AI.
Inflection, the well-funded AI foundational model startup with a bold vision of making "personal AI for everyone," recently its powerful language model fueling the Pi conversational agent. The company is backed by Microsoft, Reid Hoffman, Bill Gates, Eric Schmidt, and Nvidia.
Finally, Cohere, a Canadian startup, offers a reliable and scalable large language model designed for enterprise use. Their model caters to the specific requirements of businesses, ensuring both reliability and scalability.
Semiconductors, Chips, Cloud Hosting, Inference, Deployment
Generative AI models rely on powerful computational resources for training and generating outputs.
While I started with foundational models, GPUs and TPUs (specialized chips), along with cloud hosting, really form the base of the Generative AI infrastructure stack.
Compute, which is the ability to process data (and perform calculations), plays a critical role in AI systems. GPUs, CPUs and TPUs are different types of compute. What matters in the Generative AI stack are GPUs, which were originally designed for graphics tasks but excel in computationally intensive operations like training networks for Generative AI. GPUs are optimized for parallelized compute processing, which mean breaking down a large task into smaller tasks that can be processed simultaneously by multiple processors. AI/ML tasks are a highly parallelizable workload, thus why GPUs have made sense.
Generative AI requires substantial computational resources and large datasets, which are processed and stored in high-performance data centers. Cloud platforms like AWS, Microsoft Azure, and Google Cloud provide scalable resources and GPUs for training and deploying generative AI models.
GPU leader Nvidia recently crossed a $1 Trillion market cap, and new entrants like d-Matrix are entering the sector with performant chips for Generative AI to help with inferencing, which is the process of using a trained generative model to to make predictions on new data. d-Matrix is building a new chip for inferencing, using digital-in-memory computing (DIMC) technique to significantly lower latency-per-token vs. current compute accelerators. d-Matrix believes solving the memory-compute integration problem, is the key to improving AI compute efficiency to handle the explosion in Inferencing applications in a power and cost-efficient manner.
Lambda Labs provides large-scale GPU clusters for training LLMs and Generative AI models. Lambda is focused on providing the world’s lowest-cost GPU instances, and Lambda Labs provides cloud services to some of the world’s leading researchers, engineers, and companies. John Carmack's Keen Technologies, MIT, Berkeley, Midjourney, and others use Lambda cloud to power their AI training and inference.
CoreWeave is a specialized cloud service provider focused on highly parallelizable workloads at scale. The company has secured funding from Nvidia and the founder of GitHub. Its clients include Generative AI companies like Stability AI and it supports open-source AI and machine learning projects.
In addition, there are specialized companies dedicated to supporting Generative AI. HuggingFace, which is essentially GitHub for LLMs, offers a comprehensive AI computing resource with a collaboration platform called the Hub, facilitating model sharing and deployment on major cloud platforms.
What is interesting is that cloud providers are aligning with key foundational model players; Microsoft invested resources and significant capital in OpenAI, Google's invested in Anthropic & complements its Google Brain initiatives, and Amazon aligned with HuggingFace. The takeaway is that AWS's previous dominance based on credits and innovation is no longer the default option for companies that might want to use one of the specific foundational models.
Orchestration Layer / Application Frameworks
The next level up the stack is application frameworks that facilitate seamless integration of AI models with different data sources, empowering developers to launch applications quickly.
The key takeaway for application frameworks is that they expedite the prototyping and use of Generative AI models.
The most notable company here is LangChain, which originally started as an open-source project and then evolved into a proper startup. Their introduction of an open-source framework, specifically designed to streamline application development using LLMs. The core concept of this framework revolves around the notion of "chaining" together various components to create chatbots, Generative Question-Answering (GQA), and summarization.
I connected with Harrison Chase, the founder and CEO. He said "LangChain provides two big value adds. The first is a collection of abstractions, each representing a different module that is necessary for building complex LLM applications. These modules provide a standard interface for all integrations/implementations within that module, making it easy to switch providers with a single line of code. This helps team rapidly experiment with different model providers (OpenAI vs Anthropic), vectorstores (Pinecone vs Chroma), embedding models (OpenAI vs Cohere), and many others. The second big value add is in chains - common ways of doing more complex sequences of LLM calls to enable RAG, summarization, etc."
Another player is Fixie AI, founded by former engineering heads from Apple and Google. Fixie AI aims to establish connections between text-generating models like OpenAI's ChatGPT and enterprise-level data, systems, and workflows. For instance, companies can leverage Fixie AI to incorporate language model capabilities into their customer support workflows, where agents can process customer tickets, automatically retrieve relevant purchase information, issue refunds if required, and generate draft replies to the tickets.
Vector Databases
The next level up on the stack is the vector database which is a specialized type of database that stores data in a manner that facilitates finding similar data. It accomplishes this by representing each piece of data as a list of numbers, known as a vector.
These numbers in the vector correspond to the features or attributes of the data. For instance, if we're dealing with images, the numbers in the vector might represent the colors, shapes, and brightness of the image. Within vector databases, an important term to grasp is embeddings. Embeddings are a type of data representation that encapsulates semantic information crucial for AI to gain understanding and maintain a long-term memory, which proves vital for executing complex tasks.
Here’s a specific example. A picture of a bicycle can be efficiently converted into a series of numerical values, encompassing characteristics like size, wheel color, frame color, and handlebar color. These numerical representations facilitate seamless storage and analysis, presenting an advantage over just an image. The takeaway is that vector databases possess the ability to process and store data in a manner that is readily comprehensible to machines.
These databases can be conceptualized as tables with infinite columns.
Throughout my previous experiences building in conversational AI, I've primarily worked with relational databases that store data in tables. However, vector databases excel at representing the semantic meaning of data, enabling tasks like similarity search, recommendation, and classification.
Several companies have developed vector databases and embeddings.
Pinecone is the creator of the category. They have a distributed vector database designed for large-scale machine-learning applications. Besides Generative AI companies, it boasts customers like Shopify, Gong, Zapier, and Hubspot, providing an enterprise-grade solution with SOC 2 Type II certification and GDPR readiness. GDPR compliance matters because if a developer has to delete a record, it’s not so hard to do in a database, but it’s much more difficult to remove bad data from a model because of the way it’s structured. Pinecone also helps chat experiences with memory.
Another notable vector database is Chroma, which is a new open-source solution focused on high-performance similarity search. Chroma empowers developers to add state and memory to their AI-enabled applications. Many developers have expressed a desire for an AI tool like "ChatGPT but for their data," and Chroma serves as the bridge by enabling embedding-based document retrieval. Since its launch, Chroma has gained traction with over 35k Python downloads. Moreover, it being open-source aligns with the objective of making AI safer and more aligned.
Weaviate is an open-source vector database ideal for companies seeking flexibility. It is compatible with other model hubs such as OpenAI or HuggingFace.
Fine-Tuning
The next layer up the infrastructure stack is fine-tuning. Fine-tuning, in the realm of Generative AI, involves further training a model on a specific task or dataset. This process enhances the model's performance and adapts it to meet the unique requirements of that task or dataset. It's like how a versatile athlete focuses on specific sports to excel in it; a broad-based AI can also concentrate its knowledge on specific tasks through fine-tuning.
Developers build a new application on top of a pre-existing model. While language models trained on massive datasets can produce grammatically correct and fluent text, they may lack precision in certain areas like medicine or law. Fine-tuning the model on domain-specific datasets allows it to internalize the unique features of those areas, enhancing its ability to generate relevant text.
This aligns with the previous point on foundation models serving as platforms for other services and products. The ability to fine-tune these models is a key factor in their adaptability. Rather than starting from scratch, which requires substantial computational power and extensive data, fine-tuning an existing model streamlines the process and is cost-effective, especially if you already have large, specific datasets.
One notable company in this field is Weights and Bias.
Labeling
Accurate data labeling is crucial for the success of generative AI models.
Data can take various forms, including images, text, or audio. Labels serve as descriptions of the data. For example, an image of a bike can be labeled as "bike” or “bicycle.” One of the more tedious aspects of machine learning is providing a set of labels to teach the machine learning model what it needs to know.
Data labeling plays a significant role in machine learning, as algorithms learn from data. The accuracy of the labels directly impacts the algorithm's learning capabilities. Every AI startup or corporate R&D lab faces the challenge of annotating training data to teach algorithms what to identify. Whether it's doctors assessing the size of cancer from scans or drivers marking street signs in self-driving car footage, labeling is a necessary step.
Inaccurate data leads to inaccurate results from the models.
Data labeling remains a significant challenge and obstacle for the advancement of machine learning and artificial intelligence in many industries. It is costly, labor-intensive, and challenging for subject experts to allocate time for it, leading some to turn to crowdsourcing platforms when privacy and expertise constraints are minimal. It is often treated as “janitorial” work, even though the data is what ultimately controls model behavior and quality. In a world where most model architectures are open source, private, domain-relevant data is one of the most powerful ways to build an AI moat.
One company speeding up the labeling process is Snorkel AI. The company’s technology began as a research initiative in the Stanford AI Lab to overcome the labeling bottleneck in AI. Snorkel’s platform helps subject matter experts to label data programmatically (via a technique known as “weak supervision”) instead of manually (one-by-one), keeping humans in the loop while significantly improving labeling efficiency. This can decrease the process from months to hours or days, depending on the data complexity, and makes models easier to maintain in the long run, as training labels can be easily revisited and updated as data drifts, new error modes are discovered, or business objectives change.
“Behind every model-centric operation like pre-training and fine-tuning are the even more important data-centric operations that create the data that the model is actually learning from,” says Alex Ratner, Snorkel AI co-founder and CEO. “Our goal is to make data-centric AI development less like manual, ad hoc work and more like software development so that every organization can develop and maintain models that work on their enterprise-specific data and use cases.” Snorkel’s data-centric platform also assists with systematically identifying model errors so that labeling efforts can be focused on the slices of the data where they will be most impactful. It is used today by Fortune 500 companies in data-intensive industries such as finance, e-commerce, insurance, telecommunications, and medicine.
Labelbox is a leading AI labeling company. I spoke with Manu Sharma, CEO. Labelbox helps companies like OpenAI, Walmart, Stryker, and Google label data and manage the process. “Labelbox makes the foundational models useful in an enterprise context”. Developers use Labelbox’s model-assisted labeling to rapidly turn model predictions into new, auto-labeled training data for Generative AI use cases.
Other companies have specialized in interfaces and workforces for performing manual annotation. One of these is Scale, focusing on government agencies and enterprises. The company offers a visual data labeling platform that combines software and human expertise to label image, text, voice, and video data for companies developing machine learning algorithms. Scale employs tens of thousands of contractors for data labeling. They initially supplied labeled data to autonomous vehicle companies and expanded their customer base to government, e-commerce, enterprise automation, and robotics. Customers include Airbnb, OpenAI, DoorDash, and Pinterest.
Synthetic Data
Synthetic data, also known as artificially created data that mimics real data, offers several benefits and applications in the realm of machine learning and artificial intelligence (AI). So, why would you consider using synthetic data?
One primary use case for synthetic data arises when real data is unavailable or cannot be utilized. By generating artificial datasets that possess the same characteristics as real data, you can develop and test AI models without compromising privacy or encountering data limitations.
There are many advantages of using synthetic data.
Synthetic data safeguards privacy, as it lacks personally identifiable information (PII) and HIPAA risks. Compliance with data regulations, such as GDPR, is ensured while effectively utilizing data. It enables scalable machine learning and AI applications by generating data for training and deployment. Synthetic data enhances diversity, minimizing biases by representing various populations and scenarios, promoting fairness and inclusivity in AI models. Conditional data generation" techniques and synthetic data also address the 'cold start' problem for startups who don't have enough data to test and train models. Companies will need to synthesize proprietary datasets that are then augmented using conditional data generation techniques to fill in the edge cases they can't collect in the wild; this is sometimes called the "last mile" of model training.
When it comes to synthetic data solutions, several companies provide reliable options. Gretel.ai, Tonic.ai, and Mostly.ai are noteworthy examples in this space.
Gretel.ai allows engineers to generate artificial data sets that are based on their real data sets. Gretel combines generative models, privacy-enhancing technologies, and data metrics and reporting to enable enterprise developers and engineers to create domain-specific synthetic data on demand that is both accurate and secure. All three founders have backgrounds in cybersecurity and have worked in various roles in the US Intelligence community and their CTO was an enlisted officer, in the Air Force.
Tonic.ai, for instance, promotes their data as "real fake data," emphasizing the need for synthetic data to respect and protect the privacy of real data. Their solution finds applications in software testing, ML model training, data analysis, and sales demonstrations.
Model Supervision / AI Observability
The next level of the stack is AI observability, which is about monitoring, comprehending, and explaining the behavior of AI models. Put simply, it ensures that AI models are functioning correctly and making unbiased, non-harmful decisions.
Model supervision, which is a subset of AI observability, specifically focuses on ensuring that AI models align with their intended purpose. It involves verifying that models aren't making decisions that could be harmful or unethical.
Data drift is another important concept to consider. It refers to changes in the data distribution over time, which can result in AI models becoming less accurate. If these changes favor certain groups, the model may become more biased and lead to unfair decisions. As the data distribution shifts, the model's accuracy diminishes, potentially resulting in incorrect predictions and decisions. AI observability platforms provide solutions to tackle these challenges.
To shed light on the need for AI observability, I connected with Krishna Gade and Amit Paka, the CEO and COO of Fiddler.ai. Gade, having previously worked as an engineering leader on the Facebook News Feed, witnessed firsthand the challenges enterprises face in understanding their own machine learning models.
"As those systems became more mature and complex, it was extremely difficult to comprehend how they functioned. Questions like 'Why am I seeing this story in my feed? Why is this news story going viral? Is this news real or fake?' were hard to answer." Gade and his team developed a platform at Fiddler to address these questions, increase transparency in Facebook's models, and solve the problem of the "AI black box." Now, Krishna & Amit Paka launched Fiddler platform to help companies like Thumbtack and even In-Q-Tel (the CIA’s venture fund) with model explainability, modern monitoring, and bias detection, providing enterprises with a centralized way to manage this information and build the next generation of AI. Amit shared with me, “AI Observability has become super important for safe and responsible AI deployment. It is now a must-have for every company introducing AI products. We don't think we will have enterprise AI adoption without AI Observability which is forming the critical 3rd layer in the AI stack. “
Arize and WhyLabs are other companies that have created robust observability solutions for LLMs in production. These platform tackle adding guardrails to ensure appropriate prompts and responses for LLM applications in real time. These tools identify and mitigate malicious prompts, sensitive data, toxic responses, problematic topics, hallucinations, and jailbreak attempts in any LLM model.
Aporia is another company that emphasizes the importance of an AI observability platform, recognizing that trust can be lost in seconds and take months to regain. With a focus on customer lifetime value/dynamic pricing, Aporia is now delving into Generative AI with its LLM observability functionality.
Model Safety
At the top of the stack is model safety. One significant risk with generative AI is biased outputs. AI models tend to adopt and propagate biases present in the training data. For example, an AI resume-screening tool favored candidates with the name "Jared" and high school lacrosse experience, revealing biases in the dataset. Amazon faced a similar challenge when their AI resume screening tool exhibited an intrinsic bias towards male candidates due to the training data predominantly consisting of male employees.
Another concern is the malicious use of AI. Deep fakes, which involve the dissemination of false information through believable yet fabricated images, videos, or text, might become an issue. A recent incident involved an AI-generated image depicting an explosion at the Pentagon, causing fear and confusion among the public. This highlights the potential for AI to be weaponized for misinformation and the need for safeguards to prevent such misuse.
Additionally, unintended consequences can arise as AI systems grow in complexity and autonomy. These systems may exhibit behaviors that developers didn't anticipate, posing risks or leading to undesired outcomes. For instance, chatbots developed by Facebook started inventing their own language to communicate more efficiently, an unexpected outcome that emphasized the necessity for rigorous monitoring and safety precautions.
To mitigate these risks, techniques like bias detection and mitigation are crucial. This involves identifying biases in the model's output and implementing measures to minimize them, such as improving training data diversity and applying fairness techniques. User feedback mechanisms, where users can flag problematic outputs, play a vital role in refining AI models. Adversarial testing and validation challenge AI systems with difficult inputs to uncover weaknesses and blind spots.
Robust Intelligence aids businesses in stress-testing their AI models to avert failures. Robust Intelligence's primary offering is an AI firewall that safeguards company AI models from errors through continuous stress testing. Interestingly, this AI firewall is an AI model itself, tasked with predicting if a data point could result in an incorrect forecast.
Arthur AI debuted in 2019 with the primary aim of helping businesses monitor their machine learning models by delivering a Firewall for LLM akin to Robust Intelligence's solution. This solution monitors and enhances model precision and explainability.
CredoAI, guides businesses through the ethical ramifications of AI. Their focus lies on AI governance, allowing businesses to measure, monitor, and manage AI-generated risks at a large scale.
Finally, Skyflow provides an API-based service for securely storing sensitive and personally-identifying information. Skyflow's focuses cater to various sectors such as fintech and healthcare, assisting in securely storing critical information like credit card details.
How Does This All Fit Together?
To gain a deeper understanding of a leading company using these tools, I spoke to Will Manidis, CEO of Science.io. ScienceIO is revolutionizing the healthcare industry by building state-of-the-art foundation models built exclusively for healthcare. Hundreds of healthcare's most important organizations use ScienceIO models at the core of their workflows which gives Will a unique insight to how LLMs are being deployed in production. Here's what he's seeing:
Compute: ScienceIO relies on Lambda Labs for its computing needs, utilizing an on-premise cluster. This ensures efficient and scalable processing capabilities, in a more cost-effective way than a hyperscaler like AWS or GCP.
Foundational model: ScienceIO leverages its in-house data to create its own fundamental model. The core of their business is an API that facilitates the real-time transformation of unstructured healthcare data into structured data (named entity resolution and linking), which can then be utilized for search and analysis purposes. Many of their customers chose to chain ScienceIO alongside a more general purpose model in their workflows for tasks such as information retrevial and synthesis.
Vector: One of ScienceIO's core offerings is their embeddings product, built for high-quality embeddings for the healthcare domain. One of Will's core beliefs is that custom embeddings will become increasingly important, particularly as a complement to general-purpose models. ScienceIO uses Chroma extensively to store and query these vector embeddings.
Orchestration: For application development, ScienceIO relies on LangChain. Internal model storage, versioning, and access are powered by Huggingface.
Fine-tuning: While ScienceIO's core foundation models are de-novo trained exclusively on healthcare data, that is to say, they've never seen the piles of junk social media data or similar— many customers are interested in additional fine-tuning for their use case. ScienceIO launched Learn & Annotate, their fine-tuning and human-in-the-loop solutions to address these use-cases.
I also spoke to Pedro Salles Leite, CEO of Innerplay, which uses AI to help people and companies become more creative. Innerplay helps companies build videos in a faster way, including screenwriting.
Pedro has been studying and building AI use cases for eight years. With regards to his infrastructure stack, he said his job is making sure that the product makes sense to the user…not about setting up orchestration or foundational models – just adding another complexity. Here is his stack:
Foundation models: Innerplay uses 14 different base models to bring ideas to life. They use closed models mostly because there are "no GPUs until the product market fit".
Vector databases: Innerplay uses vector databases for tasks such as processing PDF docs. They generate a script from PDF, and vector databases are needed to accomplish this.
Fine-tuning: Innerplay hugely believes in fine-tuning. The company manually prepares datasets but plans to use AI to prepare data for fine-tuning in the future.
Prototyping: They use it to evaluate outputs and compare models. Spellbook by Scale is often used to quickly test iterations in the machine learning process before moving into Python/production.
AI observability: They are starting to think about AI observability now to improve their AI in privacy-conscious ways. Being a content creation platform. Pedro said, "Innerplay needs to make sure people use it for good”.
Conclusion
This exploration of Generative AI infrastructure only scratches the surface, and the rapid advancements in technology development and investment in the underlying foundational components are remarkable. Companies like MosaicML being acquired for staggering amounts, and the growing number of players in the field, demonstrate the immense value and interest in this space.
It’s a complex and ever-evolving landscape with multiple layers, from foundation models to fine-tuning, semiconductors to cloud hosting, and application frameworks to model supervision. Each layer plays a crucial role in harnessing the power of generative AI and enabling its applications across various industries. And in this research, many companies that start in one area expand into others.
If you want to dive deeper into these topics or have a chat, feel free to shoot me a LinkedIn direct message or email.
Great article!!!
Great article. I find the details of AI to be so interesting.